

Şu anda adlı kullanıcıyı takip ediyorsunuz
Kullanıcıyı takip etmede hata.
Bu kullanıcı kullanıcıların kendisini takip etmesine izin vermiyor.
Zaten bu kullanıcıyı takip ediyorsunuz.
Üyelik planınız sadece 0 takibe izin veriyor. Buradan yükseltme yapın.
başarılı bir şekilde takipten çıkarıldı
Kullanıcının takip edilmesinde hata.
adlı kullanıcıyı başarılı bir şekilde tavsiye ettiniz
Kullanıcıyı tavsiye etmede hata.
Bir şeyler yanlış gitti. Lütfen sayfayı yenileyin ve tekrar deneyin.
E-posta başarılı bir şekilde doğrulandı.

saharanpur,
india
Şu anda burada saat 1:36 ÖS
Kasım 4, 2012 tarihinde katıldı
3 Öneriler
Mohd T.
@tausy
6,4
6,4
97%
97%
saharanpur,
india
%96
Tamamlanmış İş
%83
Bütçe Dahilinde
%95
Zamanında
%17
Tekrar İşe Alınma Oranı
ML, AI, Data Science, Python, Hadoop, Databases
Mohd T. ile işiniz hakkında iletişime geçin
Detayları sohbet üzerinden tartışmak için giriş yapın.
Portföy
Portföy

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark

Classify Attacks and Normal Traffic Data Using PySpark


Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning

Authorship Attribution Using Machine Learning


Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment

Stock Price Prediction Using News Sentiment


FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING

FOUR SHAPES CLASSIFICATION USING DEEP LEARNING


Animals Image Classification Using Deep/Transfer Learning

Animals Image Classification Using Deep/Transfer Learning

Animals Image Classification Using Deep/Transfer Learning

Animals Image Classification Using Deep/Transfer Learning
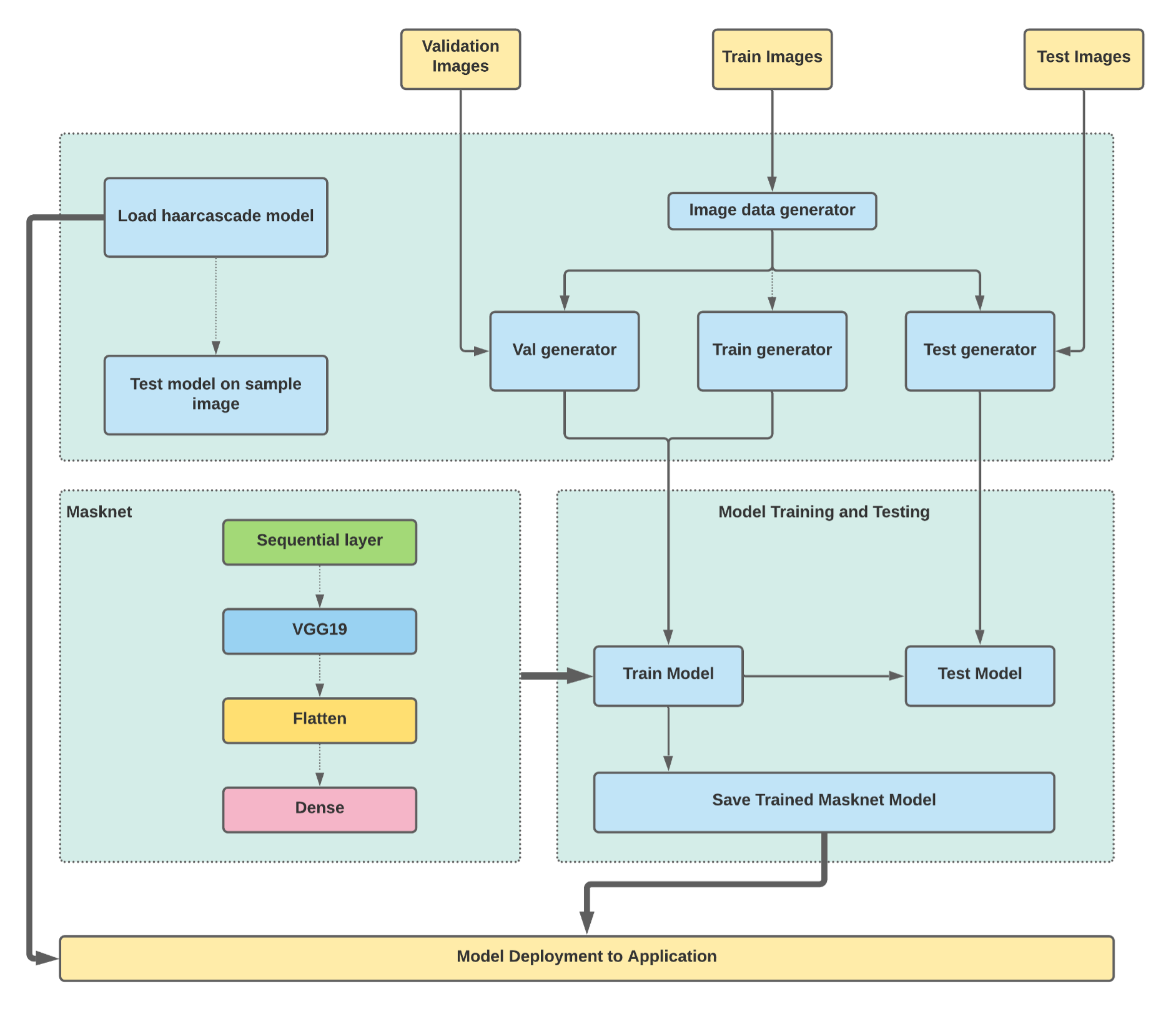

Mask Detection/Real-time Human Counting with Deep Learning

Mask Detection/Real-time Human Counting with Deep Learning

Mask Detection/Real-time Human Counting with Deep Learning
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Classify Attacks and Normal Traffic Data Using PySpark
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Authorship Attribution Using Machine Learning
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
Stock Price Prediction Using News Sentiment
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
FOUR SHAPES CLASSIFICATION USING DEEP LEARNING
Animals Image Classification Using Deep/Transfer Learning
Animals Image Classification Using Deep/Transfer Learning
Animals Image Classification Using Deep/Transfer Learning
Animals Image Classification Using Deep/Transfer Learning
Mask Detection/Real-time Human Counting with Deep Learning
Mask Detection/Real-time Human Counting with Deep Learning
Mask Detection/Real-time Human Counting with Deep Learning
Değerlendirmeler
Değişiklikler kaydedildi
50+ değerlendirme içinden 1 - 5 arasındakiler gösteriliyor
₹16.000,00 INR
Python
Machine Learning (ML)
S
•
₹20.000,00 INR
Python
Data Processing
Excel
Microsoft Access
MySQL
•
$120,00 USD
Java
Python
Machine Learning (ML)
Big Data Sales
+1 daha

•
$350,00 SGD
Python
Software Architecture
Report Writing
Machine Learning (ML)
Statistical Analysis

•
Deneyim
Hadoop/Machine Learning Developer
Eyl 2017 - Şu anda
Working on Hadoop Ecosystem in combination with python/machine learning to deliver predictive models.
Data Scientist
Ara 2019 - Şu anda
Working as a data scientist in AI/ML team.
Hadoop Developer
Nis 2016 - Ağu 2017 (1 yıl, 4 ay)
Worked on Hadoop ecosystem to deliver cutting edge predictive models using Sqoop, Flume, Oozie, Hive, Map Reduce
Eğitim
MSc Data Science
(1 yıl)
Bachelor Of Technology (Computer Engineering)
(4 yıl)
Nitelikler
Certificate in Healthcare
Tata Business Domain Academy
2014
Oracle Database Certified SQL Expert
Oracle University
2015
SQL proficiency test certificate provided by Oracle
Oracle Database Certified PL/SQL Expert
Oracle University
2015
Pl/SQL proficiency test certificate provided by Oracle
Mohd T. ile işiniz hakkında iletişime geçin
Detayları sohbet üzerinden tartışmak için giriş yapın.
Doğrulamalar
Sertifikalar
Benzer Freelancerlara Göz Atın
Benzer Vitrinlere Göz Atın
Davet başarılı bir şekilde gönderildi!
Teşekkürler! Ücretsiz kredinizi talep etmeniz için size bir bağlantı gönderdik.
E-postanız gönderilirken bir şeyler yanlış gitti. Lütfen tekrar deneyin.
Panoya kopyalama başarısız, lütfen izinlerinizi düzenledikten sonra tekrar deneyin.
Panoya kopyalandı.
Ön izleme yükleniyor
Coğrafik konum için izin verildi.
Giriş oturumunuzun süresi doldu ve çıkış yaptınız. Lütfen tekrar giriş yapın.